

In 2014, Google acquired DeepMind Technologies, a U.K.-based artificial intelligence (AI) company that has developed am advanced neural network — what is essentially the precursor to AI that can truly mimic humans. While neural networks themselves are immensely complex, the basic goal is to create a machine that can learn in a way similar to humans by mimicking the way our neurons behave and interact with one another.
In the years since the acquisition, DeepMind’s neural network has been able to improve its learning of how to play video games, making the news earlier this year when it was able to defeat a human at the territorial strategy game Go — a feat that had not previously been done.
This week, DeepMind announced something new that their neural network can do: imitate human speech. For almost a hundred years now, people have been imitating the human voice with machines called vocoders. But the speech that these machines create is unmistakably metallic and robotic. The sounds it makes do resemble the vowels and consonants we can create with our vocal chords, but ultimately a vocoder’s “speech” is a suggestion of words, a group of sounds that we can interpret as speech even though technically it isn’t speaking at all.

The ability of both vocoders and synthesized speech to more fluidly emulate human voices has improved markedly in the decades since its first creation. Text-to-speech (TTS) has vastly improved what it can do, but the concatenative TTS, which Google Now and Apple’s Siri both use, still leave us wanting something better. You see, concatenative TTS relies on a huge variety of brief speech fragments to be collected from a single subject. Those fragments are then put together by the computer when it speaks. As DeepMind pointed out in their release post, this makes it basically impossible to switch traits of the “speakers.”
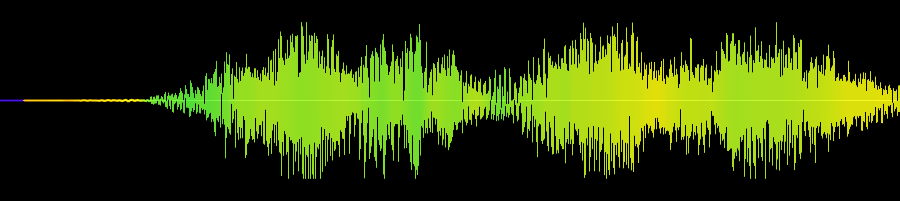
With WaveNet (what DeepMind is calling their new system), DeepMind has been able to circumvent that limitation by storing that information within the parameters of the model itself. In other words, the machine process knows how to generate these aspects of voice from scratch, rather than needing a library of samples to draw from. WaveNet creates speech at the waveform level, meaning that for every single millisecond of speech, it has uniquely generated what the waveform should look like. This results in both speech that can be manipulated by changing the model’s parameters, and speech that is much more natural than any form of speech synthesis created thus far.
Beyond speech synthesis, WaveNet can also generate music. Because it works with creating waveforms directly, DeepMind’s neural net can analyze a genre of music for example, and generate music based on that. With speech and music synthesis combined, we may eventually have entire albums created instantly by a computer that can generate an instrumental or vocal performance. As a musician myself — but one that can’t sing worth a damn — it would also be nice to give a machine vocals and have it sing them for me.
The possibilities of speech synthesis on such a minute and controllable level are nigh endless, and how exactly they’ll be utilized by the creative masses (should this sort of speech synthesis become massively accessible) will be nothing short of incredible.
If you’d like to hear samples of the different TTS types, as well as samples of the music that WaveNet created, you can visit DeepMind’s blog.





